Inari Listenmaa
![]()
GF Resource Grammar Library: Core, API and Extensions
The Resource Grammar Library (RGL) is the standard library of GF. In this post, we explore the API and the internals of the RGL, as well as the parts of the RGL that are not in the API.
Prerequisites
To appreciate this post, you should understand what this line means.
mkCl (mkNP the_Det cat_N) sleep_V
After reading this post, you will (hopefully) also understand where this tree came from,
PredVP
(DetCN (DetQuant DefArt NumSg) (UseN cat_N))
(UseV sleep_V)
and how it is related to the first line. In addition, you’ll know about the parts of the RGL that are not accessible via the API.
If you already understand both well, you can jump straight to RGL funs and lins outside the API.
If you don’t understand yet the mkCl …, I recommend that you read the GF tutorial all the way to Lesson 4, until you reach the section on functors. You can stop when you see the word functor and return to this post.
Table of Contents
- Using the RGL (API) in an application grammar
- Insides of the RGL
- History lesson
- RGL
funs andlins outside the API - Read more
- Footnotes
Using the RGL (API) in an application grammar
This is how we learn to use the RGL: open the API modules SyntaxXxx or ParadigmsXxx in our application grammar. A minimal example:
abstract Example = {
cat
Phrase ;
fun
example1_Phrase : Phrase ;
example2_Phrase : Phrase ;
}
Let’s do an English concrete for this grammar.
concrete ExampleEng of Example = open SyntaxEng,
LexiconEng,
ParadigmsEng in {
lincat
Phrase = Utt ; -- category Utt comes from SyntaxEng
lin
example1_Phrase =
mkUtt -- mkUtt, mkNP and
(mkNP this_Det -- this_Det come from SyntaxEng
dog_N -- dog_N comes from LexiconEng
) ;
example2_Phrase =
mkUtt
(mkNP many_Det
(mkN -- mkN comes from ParadigmsEng
"aardvark")
) ;
}
I trust that you have seen, and probably used, something like this before.
And you should know how to make this example multilingual: just look up the base form of the word “aardvark” in a dictionary, and change the string Eng to Ita, and you have an Italian concrete syntax.
concrete ExampleIta of Example = open SyntaxIta,
LexiconIta,
ParadigmsIta in {
lincat
Phrase = Utt ;
lin
example1_Phrase = mkUtt (mkNP this_Det dog_N) ;
example2_Phrase = mkUtt (mkNP many_Det (mkN "oritteropo")) ;
}
But where do all these mk* opers come from?
Insides of the RGL
Depending on where you learned GF, you might have seen something like the following.
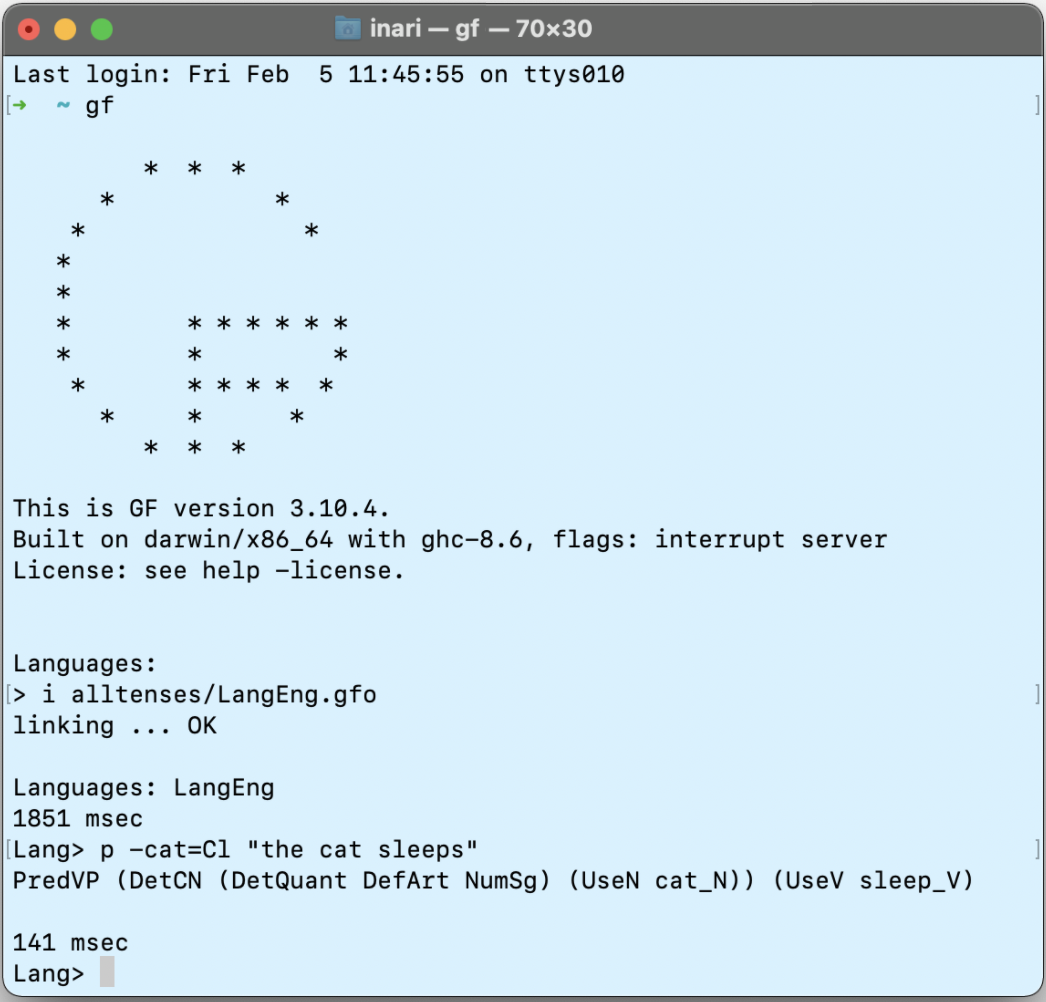
The screenshot is showing a GF shell, where I’ve opened a GF file called LangEng.gfo. Then I parsed the sentence “the cat sleeps”, and got the following abstract syntax tree.
PredVP
(DetCN (DetQuant DefArt NumSg) (UseN cat_N))
(UseV sleep_V)
This is a glimpse to the abstract syntax of the RGL. All of these words, like PredVP and DefArt, are funs in modules such as Sentence.gf or Noun.gf, and lins in their respective SentenceEng.gf, NounRus.gf or any other of the 40+ languages in the RGL.
No need to understand the linked code, I just wanted to show you how the RLG is just another GF grammar.
History lesson
Disclaimer: I only came into GF in 2010, and by then the RGL API was stable. Think of the historical details as a dramatic re-enactment.
Before RGL
Once upon a time, there was no RGL. All application grammars looked like the Foods grammar that isn’t using the RGL, or the examples from lesson 3 of the GF tutorial.
But English nouns inflect just the same, no matter if the domain is mathematics or health care. So the obvious first idea is to save those params and opers from FoodsEng, and reuse them for other English concrete syntaxes of different application grammars.
param
Number = Sg | Pl ;
oper
det : Number -> Str ->
{s : Number => Str} -> {s : Str ; n : Number} =
\n,det,noun -> {s = det ++ noun.s ! n ; n = n} ;
noun : Str -> Str -> {s : Number => Str} =
\man,men -> {s = table {Sg => man ; Pl => men}} ;
regNoun : Str -> {s : Number => Str} =
\car -> noun car (car + "s") ;
adj : Str -> {s : Str} =
\cold -> {s = cold} ;
copula : Number => Str =
table {Sg => "is" ; Pl => "are"} ;
So we save this into a resource module called ProtoRGLEng.gf. It’s a good start, but there are limitations.
Nothing requires the whole set of opers to be internally consistent. The type {s : Number => Str} is used in noun and det, but one of them could easily change, and the ProtoRGLEng module will still compile. Only when you try to compile an application grammar that uses those opers, it will stop working.
In addition, nothing requires the opers in ProtoRGLEng and, say, ProtoRGLIta to be consistent with each other. Some things are necessarily different in such opers, like inflection tables for adjective—1 form in English, 4 forms in Italian. But other choices are arbitrary, like how to implement determiners (like this, many, the). The code below illustrates two alternatives.
oper
-- Common ground: Nouns and NPs
Noun : Type ;
dog_N : Noun ;
NP : Type ; -- NPs are formed out of Nouns
-- Option 1: Determiner as a category
Det : Type ;
this_Det, many_Det : Det ;
addDet : Det -> Noun -> NP ;
-- Option 2: Determiners as functions: Noun -> NP
this, many : Noun -> NP ;
Decisions like that don’t really matter much in the grand scheme of things, but it’s annoying to try to remember which languages choose addDet this_Det dog_N and which choose this dog_N. And while we’re talking about annoying, is it really necessary to keep thinking about the details of Italian and English adjective inflection while doing syntax?
Now is there a way in GF to enforce a common, abstract idea and hide the implementation details in different languages? 🤔
Sounds like we’re better off defining this resource with abstract and concrete syntaxes.
Introducing RGL: an abstract with concretes
Now, let’s take these opers from the previous section, and redesign them as cats and funs. We want to cover nouns, determiners and noun phrases. I’ll present an almost-real subset of the RGL abstract syntax in the following. Since we already have mini and micro versions, I’ll call this the NanoRGL.
First, we have our types for determiners, nouns and noun phrases. These are proper cats, not opers.
cat
Det ; -- Determiner
N ; -- Noun
NP ; -- Noun phrase
Our lexicon and the single syntactic function are all funs. With these, our goal is to say “this dog” and “many dogs”.
fun
-- Lexicon
this_Det : Det ;
many_Det : Det ;
dog_N : N ;
-- Syntactic functions
DetN : Det -> N -> NP ;
Now that we have made this into an abstract syntax, we can do much more fun things with it! Like open it in a GF shell and generate all combinations.
NanoRGL> gt -cat=NP
DetN many_Det dog_N
DetN this_Det dog_N
Concrete syntax
I omit the concrete syntaxes in the post, but English is available on GitHub (other languages are homework). As for any GF abstract and concrete, you don’t need to know anything about the implementation details to linearise something.
NanoRGL> l DetN many_Det dog_N
many dogs
molti cani
Internal implementation of NanoRGLEng and NanoRGLIta may be different, but that doesn’t matter, because the common abstract syntax guarantees homogeneity. (Unless the grammarian is evil and decides that DetN should always ignore its arguments and just return a constant string.)
Benefits of abstract NanoRGL/concrete NanoRGLEng
The two benefits, compared to language-specific opers, are
- Internal consistency. If we change the lincat of
N, we must also change the implementations ofdog_NandDetN, otherwise the grammar won’t even compile. - Hides language-specific implementation details.
Now we have an abstract and two concrete modules. How do we use them from an application grammar?
Before RGL API
I suspect that this step is the most non-obvious one. All the time until now, we’ve seen how to use opers in definitions of lins. But here’s the news:
- You can define
lins in terms of otherlins too, not justopers. - Hence, you can use RGL without the API.
Remember the minimal application grammar from the beginning of the post? First I implemented the concrete using the RGL API. Now I’ll implement another concrete, first using our NanoRGL, and then using the actual RGL abstract syntax, not via API.
As a reminder, the abstract syntax of the application.
abstract Example = {
cat
Phrase ;
fun
example1_Phrase : Phrase ;
example2_Phrase : Phrase ;
}
The first concrete uses the NanoRGL. If you have Example and NanoRGL in the same directory, you can run this grammar perfectly fine.
concrete ExampleEngNano of Example = open NanoRGLEng in {
lincat
Phrase = NP ; -- cat in NanoRGL, lincat in NanoRGLEng
lin
example1_Phrase =
DetN -- fun in NanoRGL, lin in NanoRGLEng
this_Det -- fun in NanoRGL, …
dog_N ; -- fun in NanoRGL, …
example2_Phrase =
DetN
many_Det -- fun in NanoRGL, …
(regNoun -- oper in NanoRGLEng
"aardvark") ;
}
The second concrete uses the actual RGL, and recreates the concrete from the beginning that uses the API. Now instead of a single SyntaxEng, I need to open multiple modules, such as StructuralEng, NounEng and PhraseEng, because all these funs and lins are in different modules. In contrast, all of the mkUtt, mkNP etc. are in a single module, SyntaxEng.
concrete
ExampleEngRGLNoAPI of Example = open CatEng,
NounEng,
PhraseEng,
LexiconEng,
StructuralEng,
ParadigmsEng in {
lincat
Phrase = Utt ; -- from CatEng
lin
example1_Phrase =
UttNP -- from PhraseEng
(DetCN -- homework: where do the rest come from?
(DetQuant this_Quant NumSg)
(UseN dog_N)
) ;
}
This was a step forward, but still a bit annoying to write. So many things to import! So many long names that make no sense to non-linguists, and confuse actual linguists, because the fun and cat names are a random mix and match from different linguistic traditions.
Around 2006, there were enough people writing GF that the RGL situation was getting chaotic.
So the wise people in Gothenburg decided that maybe, after all, we need more opers. But let’s be smart this time.
RGL API, finally
We learned that it’s possible to define lins in terms of other lins. I hope you’ve had time to digest that, because here’s some more news:
- You can define
opers in terms oflins, too.
Here’s a trivial example. You can put this resource module NanoAPIEng in the same directory with the abstract and concrete NanoRGL(Eng). In NanoAPIEng, we have an oper called mkNP, which is calling the lin DetN from NanoRGLEng. Then you can open NanoAPIEng in your application and call mkNP.
resource NanoAPIEng = open NanoRGLEng in {
oper
mkNP : Det -> N -> NP = DetN ;
}
What’s so great about this? Well, a lot of things!
- We can overload opers. This means that we can have several opers called
mkNP, with different type signatures. - We can add shorthands to the most common structures, for the convenience of application grammarians.
- At the same time, we can keep the abstract/concrete as complicated as it needs to be, to accommodate the more complicated linguistic constructions.
Overloading
Suppose that we want to allow two kinds of NP: with a determiner and without. We’ll call both mkNP, and the distinguishing feature is the type signature.
resource NanoAPIEng = open NanoRGLEng in {
oper
mkNP = overload {
mkNP : Det -> N -> NP = DetN ; -- same as before
mkNP : N -> NP = \n ->
let emptyDet : Det = lin Det {s = [] ; num = Sg}
in DetN emptyDet n
} ;
}
For an explanation of lin Det, see my post on subtyping. Not essential for the rest of this post.
Let’s test this in the GF shell.
$ gf
…
> i -retain NanoAPIEng.gf
> cc mkNP (regNoun "dog")
{s = "dog"; lock_NP = <>}
> cc mkNP this_Det (regNoun "dog")
{s = "this" ++ "dog"; lock_NP = <>}
Shorthand for more complex internal structure
In our minimal NanoRGL, we had the type signature Det -> N -> NP for making noun phrases. This is a useful API,
which can stay unchanged in the resource module, even if we add more layers of indirection in the abstract/concrete modules.
Now let’s change the internals of NanoRGL! Introducing a new category CN, which is between N and NP.1 The internal abstract syntax is now this:
cat
Det ; N ; CN ; NP ;
fun
UseN : N -> CN ;
DetCN : Det -> CN -> NP ;
-- Used to be DetN : Det -> N -> NP
Actually, I can’t be bothered to make a new version of NanoRGL. I’ll just make a custom API for the full RGL! The snippet I just pasted is literally a fragment of the full RGL.
If you have your $GF_LIB_PATH set properly, you can copy and paste this file anywhere on your computer and run it in GF shell.
resource FullAPIEng = open
NounEng, -- this module comes from the actual RGL
-- To get some lexicon to play with in GF shell
StructuralEng,
LexiconEng
in {
oper
mkNP : Det -> N -> NP = \det,n ->
DetCN det (UseN n) ;
}
Here’s my new custom API. To define mkNP, I only need to open the module NounEng, but I also open StructuralEng and LexiconEng to get some words to play with in the GF shell.
Here’s what I can do in the GF shell.
$ gf
…
> i -retain FullAPIEng.gf
> cc mkNP many_Det cat_N
{s = table
ResEng.NPCase
["many" ++ "cats"; "many" ++ "cats'"; "many" ++ "cats";
"many" ++ "cats"];
a = ResEng.AgP3Pl ResEng.Neutr; lock_NP = <>}
And naturally, I can use this FullAPIEng resource module in any application grammar if I wanted to. For actual grammars, better stick to SyntaxEng though—it has many more overloaded instances2 of mkNP.
The actual lins-to-opers mapping happens in gf-rgl/src/api/Constructors.gf. It’s 1825 lines long, I’m not expecting you to read or understand it. Just know that it exists, and it defines shorthands such as this_Det = DetQuant this_Quant NumSg (that’s on line 768).
Recap
-
The opers in
SyntaxEng,SyntaxRusand any otherSyntaxXxxcome from funs and lins in the RGL internal modules, such asNounEng,PhraseRus,AdverbIta. -
Benefits to
Noun,Phrase,Adverbetc. modules as abstract syntaxes with concretes: internal consistency and hiding language-specific details. -
Benefits to an API of opers on top of the core abstract/concrete: overloading and shortcuts.
And finally, here’s a picture showing what we’ve just learned. It’s not the full picture of the intricacies of GF’s module structure3, but it shows which things are funs/lins and which are opers.

If the API had been continuously updated since the early 2000s, this blog post would end here. However, if you want to use constructions as simple as “John’s book” or “one of my friends”, you need to learn one more thing: there are funs and lins in the RGL that are not in the API.
RGL funs and lins outside the API
So, the RGL API was made in the 2000s, but the RGL has continued to develop since then. There are a number of new modules, and new funs in the old modules, that are not accessible from the API.
New functions in old modules
Some older RGL modules have added new functions that were never added to the API. For instance, the possessive and partitive constructions in Noun.gf:
--2 Possessive and partitive constructs
-- (New 13/3/2013 AR; Structural.possess_Prep and part_Prep
-- should be deprecated in favour of these.)
PossNP : CN -> NP -> CN ; -- house of Paris, house of mine
PartNP : CN -> NP -> CN ; -- glass of wine
-- This is different from the partitive, as shown by many languages.
CountNP : Det -> NP -> NP ; -- three of them, some of the boys
I’ve found a simple trick to find at least some of these in the RGL. Notice how Aarne signs the changes with the year, like New 13/3/2013 AR. If you grep for the string "201." in the directory gf-rgl/src/abstract, you will find a number of these.
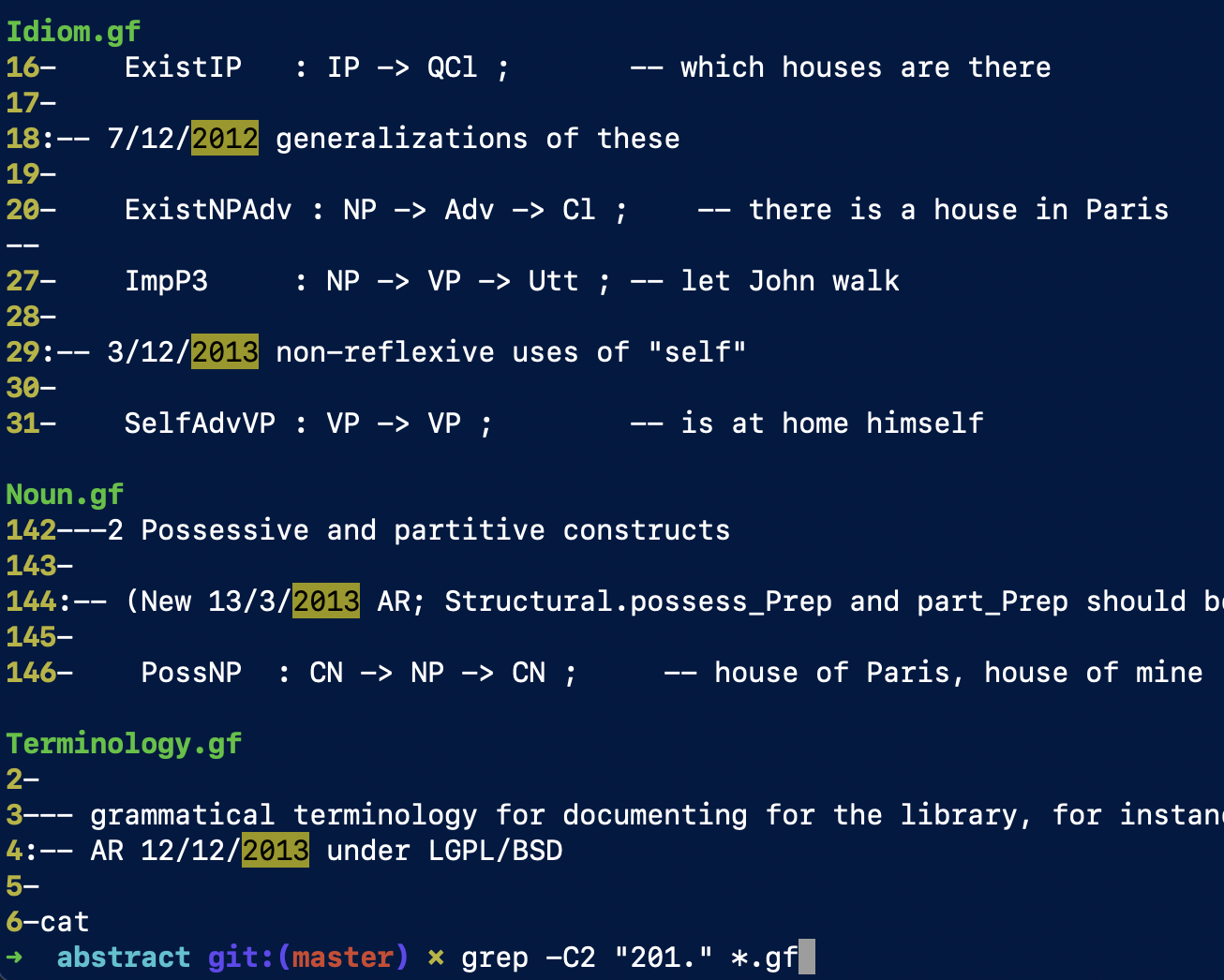
This search gives you a list of candidates. But to know for sure whether some fun is exported in the API, you need to search for it in gf-rgl/src/api/Constructors.gf. That’s where all the RGL funs are mapped to the API opers.
You can grep from command line, or view the file on GitHub and Ctrl+F the fun you’re looking for, e.g. CountNP. If you don’t find the fun in Constructors, then it’s not exported in the API, and you need to open the concrete module instead.
This is how to use CountNP in your application grammar. By now you should’ve seen that we can open concretes as well as resources.
concrete MyFriendsEng of MyFriends =
open
SyntaxEng, -- contains opers
ParadigmsEng, -- contains opers
NounEng -- contains lins
in {
lin
OneOfMyFriends_NP =
let one_Det : Det = mkDet (mkNumeral n1_Unit) ;
my_Det : Det = mkDet i_Pron pluralNum ;
friend_N : N = mkN "friend" ;
in CountNP -- from NounEng, not in API
one_Det
(mkNP my_Det friend_N) ;
}
Language-specific Extra modules
The new RGL functions from the previous section are supposed to be implemented for all RGL languages. A resource grammar without a linearisation of CountNP is incomplete.
But there are also modules that are supposed to be language-specific. For instance, take a look at the ExtraJpn module. It defines two new categories: level of politeness, and whether to use は or が to mark the subject of the sentence.
cat
Level ; -- style of speech
Part ; -- particles は (wa) / が (ga)
fun
Honorific : Level ;
Informal : Level ;
PartWA : Part ;
PartGA : Part ;
StylePartPhr : Level -> Part -> ... -> Utt -> Phr ;
These things are important grammatical distinctions in Japanese, but not for the majority of the RGL languages. So it makes sense that e.g. English doesn’t even try to linearise them.
Moreover, the logistics support this design. The abstract syntax of the language-specific Extra modules is only in the language directory. ExtraJpnAbs is in gr-rgl/src/japanese/, and it’s not supposed to have a concrete for other languages than Japanese.
I have a previous post about Japanese, where I explain how to use the ExtraJpn module in an application grammar. The link goes to the explanation of the GF module, but if you’re interested in the linguistic details, you can jump to the beginning of the linked post.
Extend
The Extend module is kind of a middle ground to language-specific extensions.
Unlike the truly language-specific Extras, it’s a common abstract syntax in gf-rgl/src/abstract/, and meant to have many concrete syntaxes.
However, it’s accepted that not all funs will have a linearisation in all concrete syntaxes.
Sometimes the function just has no meaningful linearisation. Other times, the linearisation could be something different. Consider the following fun:
-- this fun was made for German
fun UttDatNP : NP -> Utt ; -- him (dative)
In a language that has no dative, we could either leave this fun without a lin, or simply make it output the NP in some other case. If we ever parse something in German, it’s still information to get the same NP in Chinese, even though the finer points of dative is lost. So I’d do this in ExtendChi:
-- Chinese concrete syntax
lin UttDatNP = UttNP ; -- using UttNP from PhraseChi
If you look at the real Extend modules, you’ll see different strategies for different languages and different funs.
Here’s a StackOverflow answer where I explain how to use Extend in an application grammar.
Documentation of Extend
The only real documentation of Extend is in the source code of the abstract syntax. So let me describe a workflow that I use when I develop an application grammar, and need to search for a construction in Extend.
Suppose that I want to use the structure NP’s CN, like “John’s shoes”, “my dog’s food”. And right now I’m writing a concrete syntax for Dutch.
- I browse the abstract syntax of the Extend module. To be more exact, I read the comments for each construction, until I find the fun I want. It’s GenModNP
: Num -> NP -> CN -> NP“this man’s car(s)”. - I go to the Dutch concrete syntax at gf-rgl/src/dutch/ExtendDut.gf to see if it’s implemented.
- On the first glance, I don’t see the string
GenModNPin the file. So no? - But wait—look at line 4, the concrete syntax is actually an instantiation of ExtendFunctor, and the 3 explicitly named lins are actually excluded from the functor.
- I go to gf-rgl/src/common/ExtendFunctor.gf and see if there’s a default implementation for
GenModNP. - In fact, there is, on line 20!
- But… that’s just the default RGL implementation, “the car of this man”. I wanted “this man’s car”.
- I’ll implement
GenModNPfor Dutch myself! Let me consult the internet on Dutch grammar. - Huh, the internet tells me that technically you can say dezes mans auto ‘this man’s car’, but it sounds archaic, and the version de auto van deze man ‘the car of this man’ is more normal.

So… the default RGL implementation was fine after all for Dutch. I could just scrap the GenModNP and start browsing the RGL synopsis to figure out how to say the CN of NP. Or I can leave it as GenModNP in the Dutch concrete, because the default implementation does return the CN of NP. In addition to being lazy, I leave GenModNP as a reminder that I’d still prefer the construction NP’s CN for all languages where it exists (and is implemented).
Now, say that you needed some other Extend function, but it didn’t have any implementation in your language. If you have a good grasp of GF, I encourage you to poke around in the resource grammar of your language, and just try implementing the missing Extend linearisation. But if contributing to the RGL is beyond your reach at the moment, your best bet is to open an issue on the RGL repo, and explain your wish: which function you want implemented and for which language(s).
WordNet and ParseExtend
WordNet has been ported to GF as a multilingual lexicon. You can find the repository on GitHub.
In addition to the WordNet lexicon, the repository contains an extension module called ParseExtend.
Some of the funs in ParseExtend overlap with Extend, some are unique to one of the modules, and then there are funs that have the same name, but different type signatures in the two modules. (See more discussion in this issue.)
If you want to use ParseExtend and Extend in your application grammar, it’s best to open them qualified, to not confuse the names.
concrete MyAppEng of MyApp =
open
(E=ExtendEng), -- qualified open: (abbr=moduleName)
(PE=ParseExtendEng), -- must prefix all with abbr
SyntaxEng in {
lin
MyFun1 = ... E.SomeFun ... ;
MyFun2 = ... PE.SomeFun ... ;
-- You can't just call SomeFun,
-- it must be E.SomeFun or PE.SomeFun.
}
Here’s a StackOverflow answer regarding the use of WordNet.
Read more
-
I have made a tutorial on GitHub, which covers much of the same topics that this post does. I’m keeping the two as separate but overlapping resources, mostly because I want to explore different ways of explaining this topic to new GF users.
-
If you’re interested in implementing your own resource grammar, you can graduate from
NanoRGLtoMicroGrammarandMiniGrammar, in the course materials of the Computational Syntax course at the University of Gothenburg. I’ve made a series of video tutorials, which show incremental improvements to the base grammarMicroLangDummy.
Footnotes
-
Slightly offtopic for the purposes of this post, but if you’re curious about why do we need
CNin the full RGL, read on.
In addition to determiners, nouns and noun phrases, we have a categoryCN, common noun. It’s there to allow modifiers that can be piled on. Adjectives are an example of such modifiers: you can say “big old red house” in standard English. Determiners are not: you can’t say “*the a my house”.
SinceNis strictly a lexical category, we need an intermediate categoryCNthat can be modified by adding e.g. adjectives (big house), adverbs (house on the hill) or relative clauses (house that was sold). It’s not aNPyet, because it doesn’t have a determiner, but I hope you agree that “big house” is not just a noun anymore. HenceCN.
So adjectives and other such modifiers were the justification for adding an intermediate categoryCN. But we still want to allow also noun phrases without adjectives: “this dog”, not just “this small dog”. Ideally, we want a single rule to turn “dog” and “small dog” into aNP. That is possible, if we allow the smallestCNto be just a noun. That’s why we have the seemingly useless functionUseN : N -> CN. ↩ -
“Overload instance” just means all the different arguments you can give to an overloaded oper. For example,
mkNP : N -> NPis one overload instance, andmkNP : Det -> CN -> NPis another. ↩ -
GF has other kinds of module than just
abstract,concreteandresource. I have deliberately avoided talking about those parts of the GF module structure, and I will continue to do so. But if you look at the actual files in the RGL API, you’ll see words likeinterface,instance,incomplete resource. If you want to know what those things mean, you can read the GF tutorial from when you first encountered the word functor. ↩